수치 컴퓨팅 및 GPU 프로그래밍 과제 2 공지 게시판입니다.
과제 2과 관련된 내용, 질문에 대한 답을 정리하여 업데이트 할 것입니다.
자세한 내용은 수업 시간에 나눠준 문서를 참조하시면 됩니다.
○제출 형식
-과제 제출 메일 : 2018numeric@gmail.com (파일 전송 문제로 사용 X)
ajp5050@daum.net
-이메일 제목 : HW2_S[학번]_[이름]
ex) HW2_S320150054_안재풍
-파일 압축명 : HW2_S[학번]_[이름].zip
ex) HW2_S320150054_안재풍.zip
○채점 기준
1) 프로그램
- 목적과 요구사항에 맞도록 프로그램을 작성
- 4개의 커널 프로그램은 각각 부분적으로 채점
- CPU나 GPU 커널에서 결과 값 자체를 틀리게 출력한다면 해당 부분 0점
- 채점 시 Release 모드로 컴파일하여 채점합니다. 해당 모드에서 컴파일 및 런타임 에러시 0점
- OpenCL 라이브러리는 다음의 위치에 있다고 가정하고 채점합니다. 이를 고려하지 않았다면 감점
헤더 파일 : C:\usr\local\OpenCL\include;
라이브러리 : C:\usr\local\OpenCL\lib\x86_64; (64bit)
C:\usr\local\OpenCL\lib\x86; (32bit)
- 채점 환경은 Visual Studio 2017을 기준으로 합니다.
- GPU를 사용할 수 있는 윈도우 환경이 없는 경우에 한해 cmake 빌드 시스템 사용을 허용합니다.
* 되도록이면 권장하지는 않습니다.
* cmake 툴을 사용하여 Visual studio 2017 솔루션 파일로 변형 후 채점하는 것을 기준으로 합니다.
* cmake 빌드 시스템을 사용 할 시, 보고서에 명시하여야 합니다.
* 변형된 프로젝트 파일은 위의 채점 기준을 따라야 하며, 변환된 프로젝트 파일에 이상이 있는 경우 불이익이 있을 수 있습니다.
----------------------------------------------------------------
# 2018/05/06
Fortran 컴파일 문제로 32bit Release 허용
----------------------------------------------------------------
2) 보고서
- 작성된 프로그램의 실행 결과를 분석
- 보고서에 실험환경을 기술
- 속도 측정 결과는 표나 그래프와 같은 형태로 나타내어 비교할 수 있도록 표시
- 속도 측정 결과가 실험한 결과처럼 나온 이유를 서술
- 이 또한 각 항목에 대하여 부분적으로 채점
3) 기타
- 채점은 보고서인 Readme 파일을 기준으로 채점, 미기재시 해당 부분을 채점하지 않을 수도 있음
- 파일 이름 및 메일 형식 오타 시 감점
- 구글 드라이브 등과 같은 클라우드 드라이브 링크는 받지 않습니다. (미제출 처리)
- 알집 사용으로 인해 압축이 깨진 상태로 전송하면 채점을 할 수가 없습니다. (미제출 처리)
- Copy의 경우 문서에 적힌대로 불이익이 있습니다.
○질문 및 답변
--------------------------------------------------------------------------------------------------------------------------------
# 2018/05/14 추가
Q : CPU 상에서의 구현?
A :
CPU 상에서의 구현은 C++로 하면 됩니다.
(멀티쓰레딩이나 OpenCL CPU 커널도 되기는 합니다만...)
C++에서 데이터를 넘기는 방법은 2가지(OpenGL/CL)가 있습니다.
- OpenCL 관점
OpenCL에서는 clEnqueueWriteBuffer라는 함수를 통해 데이터를 넘길 수 있습니다.
// 권한 얻어옴 (OpenGL -> OpenCL)
glFlush();
glFinish();
errcode_ret = clEnqueueAcquireGLObjects(cmd_queue, 2, buf_pos, 0, nullptr, nullptr);
CHECK_ERROR_CODE(errcode_ret);
errcode_ret = clEnqueueAcquireGLObjects(cmd_queue, 2, buf_vel, 0, nullptr, nullptr);
CHECK_ERROR_CODE(errcode_ret);
errcode_ret = clEnqueueAcquireGLObjects(cmd_queue, 1, &buf_normal, 0, nullptr, nullptr);
CHECK_ERROR_CODE(errcode_ret);
CHECK_TIME_START;
// Position, Velocity 계산 (실제로 구현해야 할 부분)
CalcPosition(position, velocity);
// Position, Velocity 데이터 넘김 (CPU -> GPU)
errcode_ret = clEnqueueWriteBuffer(cmd_queue, buf_pos[0], CL_FALSE, 0, 4 * buffer_size * sizeof(GLfloat), &position[0], 0, NULL, NULL);
CHECK_ERROR_CODE(errcode_ret);
errcode_ret = clEnqueueWriteBuffer(cmd_queue, buf_vel[0], CL_FALSE, 0, 4 * buffer_size * sizeof(GLfloat), &velocity[0], 0, NULL, NULL);
CHECK_ERROR_CODE(errcode_ret);
// 넘긴 데이터로부터 Normal 구함 (이 부분은 렌더링을 위한 부분으로 이번 과제에서 고정)
errcode_ret = clSetKernelArg(kernel[1], 0, sizeof(cl_mem), &buf_pos[0]);
errcode_ret |= clSetKernelArg(kernel[1], 1, sizeof(cl_mem), &buf_normal);
errcode_ret |= clSetKernelArg(kernel[1], 2, 4 * (WORKGROUP_SIZE_X + 2) * (WORKGROUP_SIZE_Y + 2) * sizeof(float), NULL);
CHECK_ERROR_CODE(errcode_ret);
errcode_ret = clEnqueueNDRangeKernel(cmd_queue, kernel[1], 2, nullptr, global_work_size, local_work_size, 0, nullptr, nullptr);
CHECK_ERROR_CODE(errcode_ret);
clFinish(cmd_queue);
CHECK_TIME_END(compute_time);
- OpenGL 관점
OpenGL을 배웠다면 다음과 같이 데이터를 넘겨줄 수도 있습니다.
CHECK_TIME_START;
// Position, Velocity 계산 (실제로 구현해야 할 부분)
CalcPosition(position, velocity);
// Position, Velocity 데이터 넘김 (CPU -> GPU)
glBindBuffer(GL_ARRAY_BUFFER, loc_curr_pos);
glBufferData(GL_ARRAY_BUFFER, 4 * buffer_size * sizeof(GLfloat), &position[0], GL_DYNAMIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, loc_curr_vel);
glBufferData(GL_ARRAY_BUFFER, 4 * buffer_size * sizeof(GLfloat), &velocity[0], GL_DYNAMIC_COPY);
// 권한 얻어옴 (OpenGL -> OpenCL)
glFlush();
glFinish();
errcode_ret = clEnqueueAcquireGLObjects(cmd_queue, 2, buf_pos, 0, nullptr, nullptr);
CHECK_ERROR_CODE(errcode_ret);
errcode_ret = clEnqueueAcquireGLObjects(cmd_queue, 2, buf_vel, 0, nullptr, nullptr);
CHECK_ERROR_CODE(errcode_ret);
errcode_ret = clEnqueueAcquireGLObjects(cmd_queue, 1, &buf_normal, 0, nullptr, nullptr);
CHECK_ERROR_CODE(errcode_ret);
// 넘긴 데이터로부터 Normal 구함 (이 부분은 렌더링을 위한 부분으로 이번 과제에서 고정)
errcode_ret = clSetKernelArg(kernel[1], 0, sizeof(cl_mem), &buf_pos[0]);
errcode_ret |= clSetKernelArg(kernel[1], 1, sizeof(cl_mem), &buf_normal);
errcode_ret |= clSetKernelArg(kernel[1], 2, 4 * (WORKGROUP_SIZE_X + 2) * (WORKGROUP_SIZE_Y + 2) * sizeof(float), NULL);
CHECK_ERROR_CODE(errcode_ret);
errcode_ret = clEnqueueNDRangeKernel(cmd_queue, kernel[1], 2, nullptr, global_work_size, local_work_size, 0, nullptr, nullptr);
CHECK_ERROR_CODE(errcode_ret);
clFinish(cmd_queue);
CHECK_TIME_END(compute_time);
따라서 위와 같은 방법을 통해 CPU 데이터를 처리하면 됩니다.
Q : Position에 float4를 사용한 이유는 무엇이며, 어떻게 값을 넣어야 하나요?
A : GPU에서는 align으로 인해 실제로는 float3과 float4가 같습니다.
즉, float3 버퍼는 실제로 float 4개만큼 공간을 가지며, 마지막 값은 패딩으로 쓰는 것과 같습니다.
아핀 공간에서의 좌표이므로, 마지막 값은 1.0으로 처리하면 됩니다. (초기화 한 값)
Q : 시뮬레이션은 최대 10초동안 진행하라고 했는데 그 뒤는 어떻게 처리해야 하나요?
A : 10초까지만 진행하고 싶다면 거기까지만 계산하면 됩니다.
채점할 때는 조금 더 진행해도 감점하지는 않습니다.
종료(exit(0))는 호출하지 마십시오.
Q : local과 global의 차이가 거의 나지 않습니다.
A : 해당 부분은 메모리 접근에 따라 차이가 날 수 있습니다.
데이터 접근의 비율이 적으면 당연하게도 별로 차이가 나지 않습니다.
Q : 구현한 코드마다 수행 속도가 달라 시간에 대해 분석할 수 없습니다. 기준을 무엇으로 해야 할까요?
A : 실제 수행속도가 아닌, 계산에 사용한 T 값 기준입니다.
즉, 시뮬레이션에서의 시간입니다.
Q : 문항 2-(f) 에서는 어떤 코드를 사용해야 하나요?
A :
해당 부분은 분석 부분에 해당하는 부분으로, 보고서에 쓰는 부분은 방법 1, 2, 3 중 하나만 써도 상관은 없을 것입니다.
(대체로 복잡하게 구현된 방법 3이 될 것입니다만...)
하지만 2-(e)에서 세 방법을 비교하려면 최적화된 상태에서 비교해야 하기 때문에, 실제로는 다 적는 것과 거의 같습니다.
잘 모르시겠다면 세 방법 모두 적으시면 됩니다.
Q : 분석은 어떻게 해야 하나요?
A :
수업때도 설명 하였듯이, Workgroup의 크기/구성과 Local Memory, Register 등이 수행속도에 영향을 줍니다.
때문에 비교를 통해 특정 구성을 사용할 시 속도가 빠른지를 알아내고, 왜 그 때 빠른지에 대한 이유와 적는다면 이것이 분석이 됩니다.
--------------------------------------------------------------------------------------------------------------------------------
# 2018/05/15 추가
Q : CPU 상에서의 구현은 어떤 언어로 하면 되나요?
A :
CPU 상에서의 구현은 C++로 하면 됩니다.
(멀티쓰레딩이나 OpenCL CPU 커널도 되기는 합니다만...)
구한 결과를 위의 답변처럼 GPU로 넘겨주면 됩니다.
Normal을 구하고 OpenGL로 넘겨주는 부분은 렌더링 부분으로, 이번 과제에서 해야 할 것이 아니기 때문에,
Position과 velocity를 구하고, 위에서 언급한 것 처럼 이 값을 렌더링 부분으로 넘겨주면 됩니다.
--------------------------------------------------------------------------------------------------------------------------------
# 2018/05/17 추가
Q : 4-5차 Runge-Kutta fortran 프로그램(rkf45)은 어떻게 구동해야 하나요?
A :
프로젝트 내에서 rkf45.o와 rkf45.h를 복사하여 원하는 프로젝트 내에 복사합니다.
그 뒤 프로젝트 속성에서 구성 속성 -> 링커 -> 입력 -> 추가 종속성 -> rkf45.o 를 다음과 같이 추가합니다.
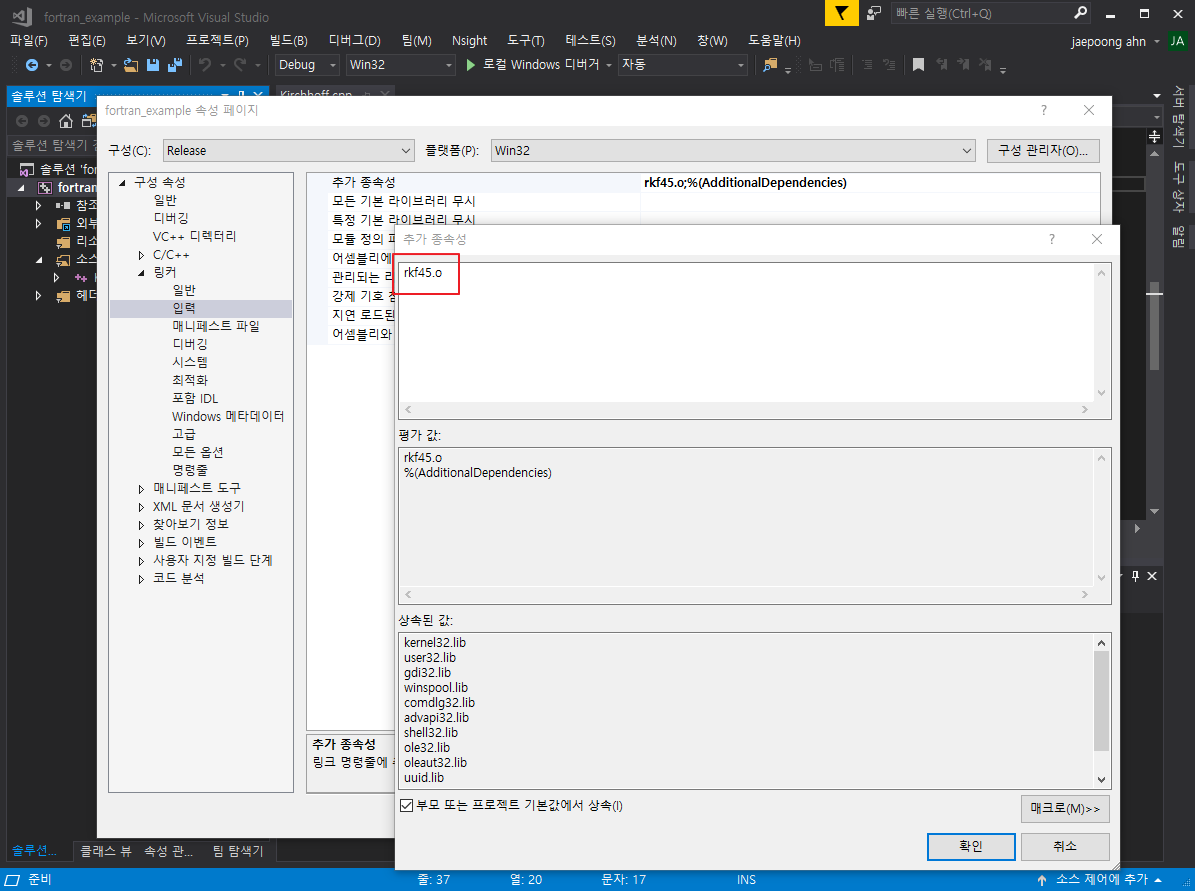
그리고 SAFESEH를 끕니다.
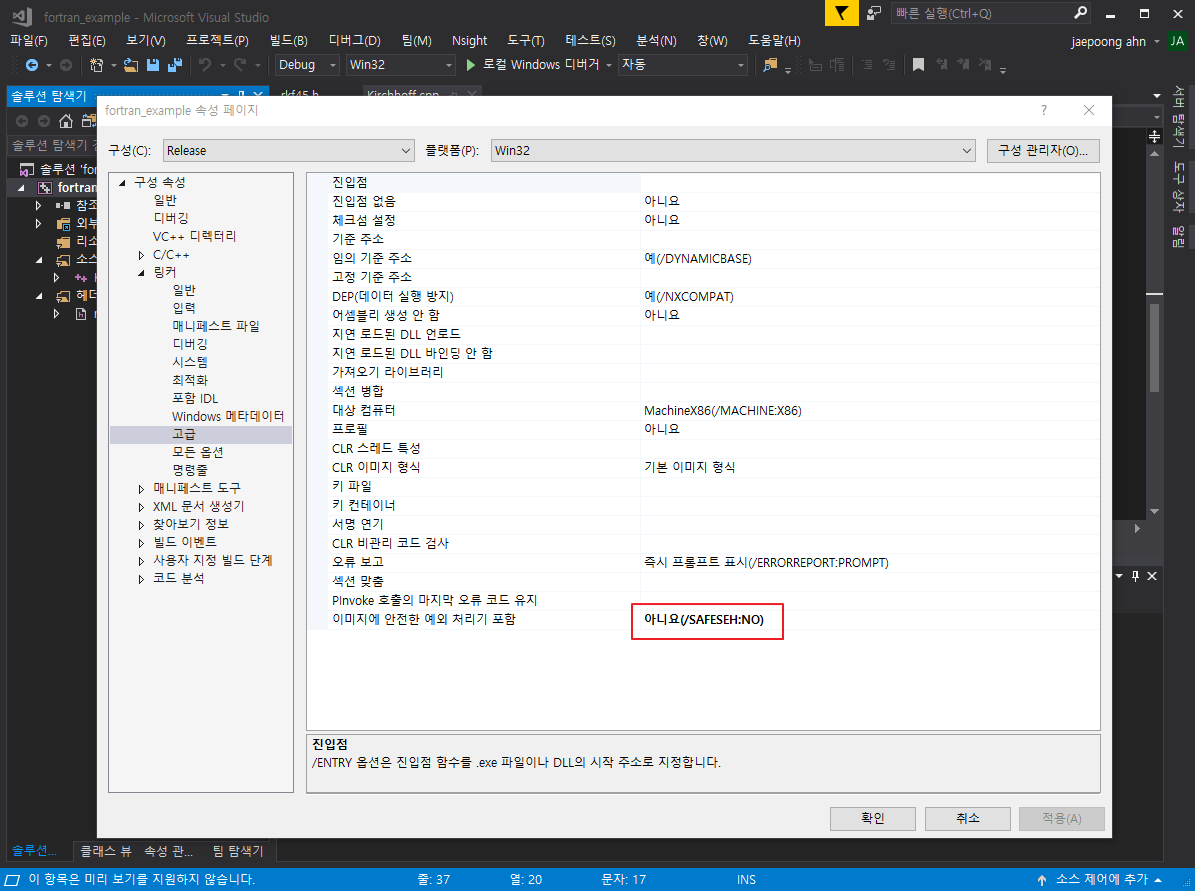
그 뒤 프로젝트에 rkf45.h를 추가하면 rkf45_() 함수를 사용할 수 있습니다.
해당 함수의 내용은 ODE 강의자료 33~35 페이지나 rkf45.f 파일의 주석에 적혀있습니다.
Q : rkf45 예제는 무엇을 의미하고, 어떻게 사용해야 하나요?
A :
첫 번째 인자에 해당하는 함수 포인터는 t(time)과 y를 받아 y'를 계산하는 함수를 의미합니다.
예제에서의
yp[0] = -4.0*y[0] + 3.0*y[1] + 6.0;
yp[1] = -2.4*y[0] + 1.6*y[1] + 3.6;
의 경우
y'_0 = -4.0 * y_0 + 3.0 * y_1 + 6.0
y'_1 = -2.4 * y_0 + 1.6 * y_1 + 3.6
을 의미합니다.
두번째 인자인 NEQN은 미분 방정식에서의 식의 갯수입니다.
세번째 인자인 y는 계산된 결과를 반환합니다.
해당 코드 부분은 예제 프로그램을 참고하면 됩니다.
예제 프로그램에서의 식에 해당하는 해는
y_0 = -3.375*e^(-2*t) + 1.875*e^(-0.4*t) + 1.5
y_1 = -2.25*e^(-2*t) + 2.25*e^(-0.4*t)
이며, 미분 방정식에서는 이를 알 수 없는 경우가 많습니다.
예제 프로그램에서는 계산된 결과를 출력하고,
계산된 결과와 실제 식에 값을 넣은 결과의 차이를 비교하고 있습니다.
--------------------------------------------------------------------------------------------------------------------------------
# 2018/05/19 추가
Q : rkf45에서 연속적이지 않은 함수를 다루려고 합니다. 어떻게 구현할 수 있을까요?
A : 방정식의 형태로 사용하지 않더라도 사용은 가능합니다.
t의 값이나 y의 값을 분기문으로 나누어 값을 지정할 수 있습니다.
Q : rkf45로 나온 결과 값이 방법1, 방법 2, 방법 3과 비슷하거나 잘 나오지 않습니다.
A : F의 값이 변동하는 것을 고려하지 않고 작성한다면 방법2와 비슷하게 나올 것입니다.
만약 F의 값이 변하는 것을 고려하여 작성하기 어렵다면, 그 상태로라도 작성하여 제출하여 주십시오.
(과제 중 CPU 부분이 방법4와 비교하는 것이기 때문에, 그 상태로라도 비교를 하여야 합니다.)
제가 구현해 돌려본 바로는 작은 interval 으로도 안정적으로 나옵니다.
Q : rkf45의 결과 값이 이상합니다.
A : rkf45의 결과 값인 iflag가 무슨 값을 가지는지 확인해야 합니다.
포트란 실행하기 전에 iflag를 설정하여 어떻게 실행할 지 결정할 수 있는데,
iflag = 1 이면 rkf45 함수가 간격이 크다고 판단할 경우 간격을 더 잘게 쪼개어 Runge-kutta 방법을 수행합니다.
iflag = -1이면 rkf45 함수가 주어진 interval에 대해서 Runge-kutta 방법을 수행합니다.
rkf45 함수를 수행 한 후에 나오는 iflag값을 통해 제대로 수행했는지 확인할 수 있습니다.
iflag = 2이면 정상적으로 수행
iflag = -2이면 단일 스텝으로는 실행했으나, 부족하므로 iflag = 1로 해서 한번 더 돌려야 함
iflag = 3이면 Error 값을 좀 더 크게 주어야 함
iflag = 4이면 iflag를 그대로 두고 한번 더 실행
iflag = 7이면 iflag를 2로 두고 한번 더 실행
iflag = 8이면 인자를 잘못 넣었으니 확인
따라서 계산 이후 iflag가 2가 나오는지를 확인해야 하며
위의 에러를 잘 처리한다면 rkf45 함수를 잘 다룰 수 있습니다.
자세한 내용은 같이 첨부된 rkf45.f를 참고하시면 좋습니다.
--------------------------------------------------------------------------------------------------------------------------------
ChangeLog
----------------------------------------------------------------
# 2018/05/19
과제 질문에 대한 답변 추가
----------------------------------------------------------------
# 2018/05/17
과제 질문에 대한 답변 추가
----------------------------------------------------------------
# 2018/05/15
과제 질문에 대한 답변 추가
----------------------------------------------------------------
# 2018/05/14
과제 질문에 대한 답변 추가
----------------------------------------------------------------
# 2018/05/06
Fortran 컴파일 문제로 32bit Release 허용
----------------------------------------------------------------
# 2018/05/04
과제 시작 및 공지
----------------------------------------------------------------
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 과제 4 (2018/06/26 18:30 수정) | grmanet | 2018.06.12 | 502 |
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 과제 3 (2018/06/26 17:00 수정) | grmanet | 2018.06.04 | 518 |
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 기말고사 | grmanet | 2018.06.04 | 226 |
| » | 수치 컴퓨팅 및 GPU 프로그래밍 - 과제 2 (2018/05/19 21:30 수정) | grmanet | 2018.05.03 | 1041 |
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 중간고사 | grmanet | 2018.04.09 | 331 |
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 과제 1 (2018/04/12 19:50 수정) | grmanet | 2018.03.29 | 1698 |
| 공지 | 2018 1학기 수치 컴퓨팅 및 GPU 프로그래밍 게시판입니다. | grmanet | 2018.03.29 | 331 |
| 2 |
OpenCL Workgroup 구성과 데이터 접근 (2018.04.12 16:40 수정)
| grmanet | 2018.04.12 | 303 |
| 1 |
OpenCL 코드 플랫폼 설정 방법
| grmanet | 2018.04.04 | 776 |