수치 컴퓨팅 및 GPU 프로그래밍 과제 1 공지 게시판입니다.
과제 1과 관련된 내용, 질문에 대한 답을 정리하여 업데이트 할 것입니다.
자세한 내용은 1803HW1.pdf를 참조하시면 됩니다.
○제출 형식
-과제 제출 메일 : 2018numeric@gmail.com
-이메일 제목 : HW1_S[학번]_[이름]
ex) HW1_S320150054_안재풍
-파일 압축명 : HW1_S[학번]_[이름].zip (또는 .zzip)
ex) HW1_S320150054_안재풍.zip
○채점 기준
1) 프로그램
- 목적과 요구사항에 맞도록 프로그램을 작성
- 4개의 커널 프로그램은 각각 부분적으로 채점
- CPU나 GPU 커널에서 결과 값 자체를 틀리게 출력한다면 해당 부분 0점
- 채점 시 64bit Release 모드로 컴파일하여 채점합니다. 해당 모드에서 컴파일 및 런타임 에러시 0점
- OpenCL 라이브러리는 다음의 위치에 있다고 가정하고 채점합니다. 이를 고려하지 않았다면 감점
헤더 파일 : C:\usr\local\OpenCL\include;
라이브러리 : C:\usr\local\OpenCL\lib\x86_64;
- 채점 환경은 Visual Studio 2017을 기준으로 합니다.
--------------------------------------------------------------------------------------------------------------------------------
# 2018/03/30 추가
- GPU를 사용할 수 있는 윈도우 환경이 없는 경우에 한해 cmake 빌드 시스템 사용을 허용합니다.
(되도록이면 권장하지는 않습니다.)
- 다만 채점시 컴파일 옵션이나 컴파일러에 따라 불이익이 없도록 채점하여야 하기 때문에
cmake 툴을 사용하여 visual studio 2017 프로젝트 파일로 변형 후 채점합니다.
- cmake 빌드 시스템을 사용하는 경우 메일과 Readme 보고서에 명시를 하여야 합니다.
- 변형된 프로젝트 파일은 위의 채점 기준을 따라야 하며, 변형된 프로젝트 파일에 이상이 있는 경우 불이익이 있을 수 있습니다.
--------------------------------------------------------------------------------------------------------------------------------
# 2018/04/04 추가
- 이번 과제에서는 OpenCL 플랫폼과 디바이스 설정 부분은 따로 명시하지 않았기 때문에,
이 부분에 한해서는 조교가 수정하여 채점할 것입니다.
- 예제 코드가 구동되지 않는다면, http://grmanet.sogang.ac.kr/xe/index.php?mid=gpu18&document_srl=1116 을 참조하시기 바랍니다.
--------------------------------------------------------------------------------------------------------------------------------
2) 보고서
- 작성된 프로그램의 실행 결과를 분석
- 속도 측정 결과는 표나 그래프와 같은 형태로 나타내어 비교할 수 있도록 표시
- 속도 측정 결과가 실험한 결과처럼 나온 이유를 서술
- 이 또한 각 항목에 대하여 부분적으로 채점
3) 기타
- 채점은 보고서인 Readme 파일을 기준으로 채점, 미기재시 해당 부분을 채점하지 않을 수도 있음
- 파일 이름 및 메일 형식 오타 시 감점
--------------------------------------------------------------------------------------------------------------------------------
# 2018/04/11 추가
- 구글 드라이브 등과 같은 클라우드 드라이브 링크를 보내는 경우는 당연하게도 변조 가능성이 있기 때문에 받지 않습니다.
절대 드라이브 링크로 보내지 마십시오!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
--------------------------------------------------------------------------------------------------------------------------------
# 2018/04/12 추가
- 되도록이면 알집으로 압축하지 마십시오.
압축파일이 깨지면 채점을 하지 않습니다!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
실제로도 압축파일이 깨져서 과제가 망가진 상태로 제출된 사례가 있습니다...
(저도 학부 때 경험을 해봤습니다... 압축하더라도 잘 풀어지는지 확인하고 보내야 합니다.)
--------------------------------------------------------------------------------------------------------------------------------
4) Gmail 관련 문의
Gmail로 메일을 보내는 경우 dll 및 exe 파일에 대해 수신 및 발신 제한이 있습니다.
메일을 보낼 때, 다음과 같은 폴더를 제거하고 보내시기 바랍니다.
- 솔루션 파일이 있는 폴더에서 .vs 폴더와 x64, Debug, Release 폴더를 삭제합니다.
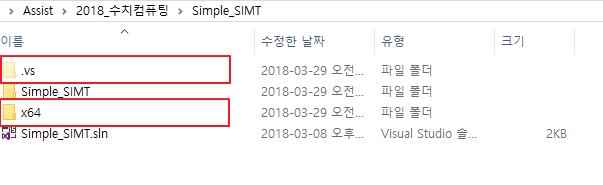
- 프로젝트 파일이 있는 폴더에서 x64, Debug, Release 폴더를 삭제합니다.
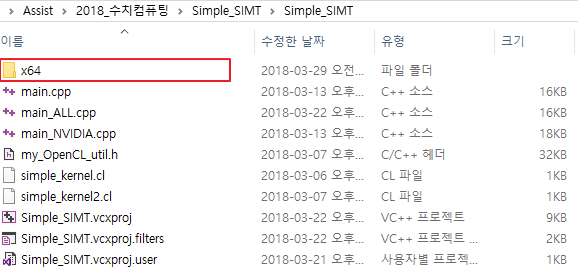
- 그 뒤 압축을 해서 보냅니다.
- 만일 그래도 반송이 된다면 확장자를 .zzip으로 변경해서 보내시면 됩니다.
아래와 같이 체크하면 확장자를 볼 수 있어 이름 변경으로 확장자를 변경할 수 있습니다.

○ 질문 및 답변
--------------------------------------------------------------------------------------------------------------------------------
# 2018/04/04 추가
Q : CPU에서 입력 배열 데이터를 2차원으로 구성할 때, OpenCL Kernel로 어떻게 보낼 수 있나요?
A : 1차원으로 줄인 뒤에 OpenCL Kernel 에서 2차원 배열처럼 접근하면 됩니다. (이미지가 아닌 그냥 버퍼이므로...)
예를 들어 A[ i ][ j ]의 경우에는 A[ i * width + j ]의 형태로 사용할 수 있습니다.
--------------------------------------------------------------------------------------------------------------------------------
# 2018/04/06 추가
Q : WorkGroup에서 나온 부분 합은 어떻게 처리를 해야 하나요?
A : 두 가지 방법이 있습니다.
첫 번째 방법은 나온 부분 합을 다시 OpenCL커널을 사용하여 GPU에서 마저 합해주는 것입니다. (GPU에서 모두 계산)
두 번째 방법은 나온 부분 합을 CPU에서 받아 CPU에서 합해주는 것입니다. (CPU에서 부분합 계산)
어느 쪽을 선택하는가에 상관 없이 부분합까지는 OpenCL을 이용하여 GPU에서 구해야 하며,
시간 측정은 당연하게도 Kernel을 수행하는 것부터 CPU에서 총 합을 구하는/받아오는 부분 까지를 측정해야 합니다.
시간 측정시 clFinish등을 이용하여 시작부분과 끝 부분에서 Host와 Device간에 동기화를 하여야 합니다.
(시작할 때 OpenCL이 백그라운드에서 이미 구동하는 것을 방지하고, 끝날 때 OpenCL Kernel이 완료되는 것을 기다림)
어떤 식으로 구현했는지는 Readme 파일에 명시하십시오.
Q : Reduction의 결과 값은 모두 Scalar 값인가요?
A : 네, 결과적으로는 수치 오차가 없다는 전제하에는 네 커널 모두 같은 값을 출력해야 합니다.
(연산 순서에 의한 수치 오차로 인해 약간은 값이 달라질 수 있습니다만, 거의 비슷한 값이 나옵니다.)
Q : Intel 내장 그래픽을 사용하는 경우
● 과연 커널 내에서 synchonization 관련 함수 호출 부분을 제거할 경우에도 올바른 reduction 결과를 산출하는지 확인하라.
만약 work-group의 크기를 64 (AMD GPU) 또는 32(NVIDIA GPU)로 할 경우에도 그러한 함수 호출이 필요한지 확인하라.
부분을 어떻게 해야 하나요?
A : 해당 부분은 R912/R914 랩실에 NVIDIA GPU가 있을 것이기 때문에, 그 부분만 랩실에서 실험 하시면 됩니다.
Q : Visual Studio에서 64bit를 어떻게 사용하나요?
A : 다음 그림을 참고하십시오.
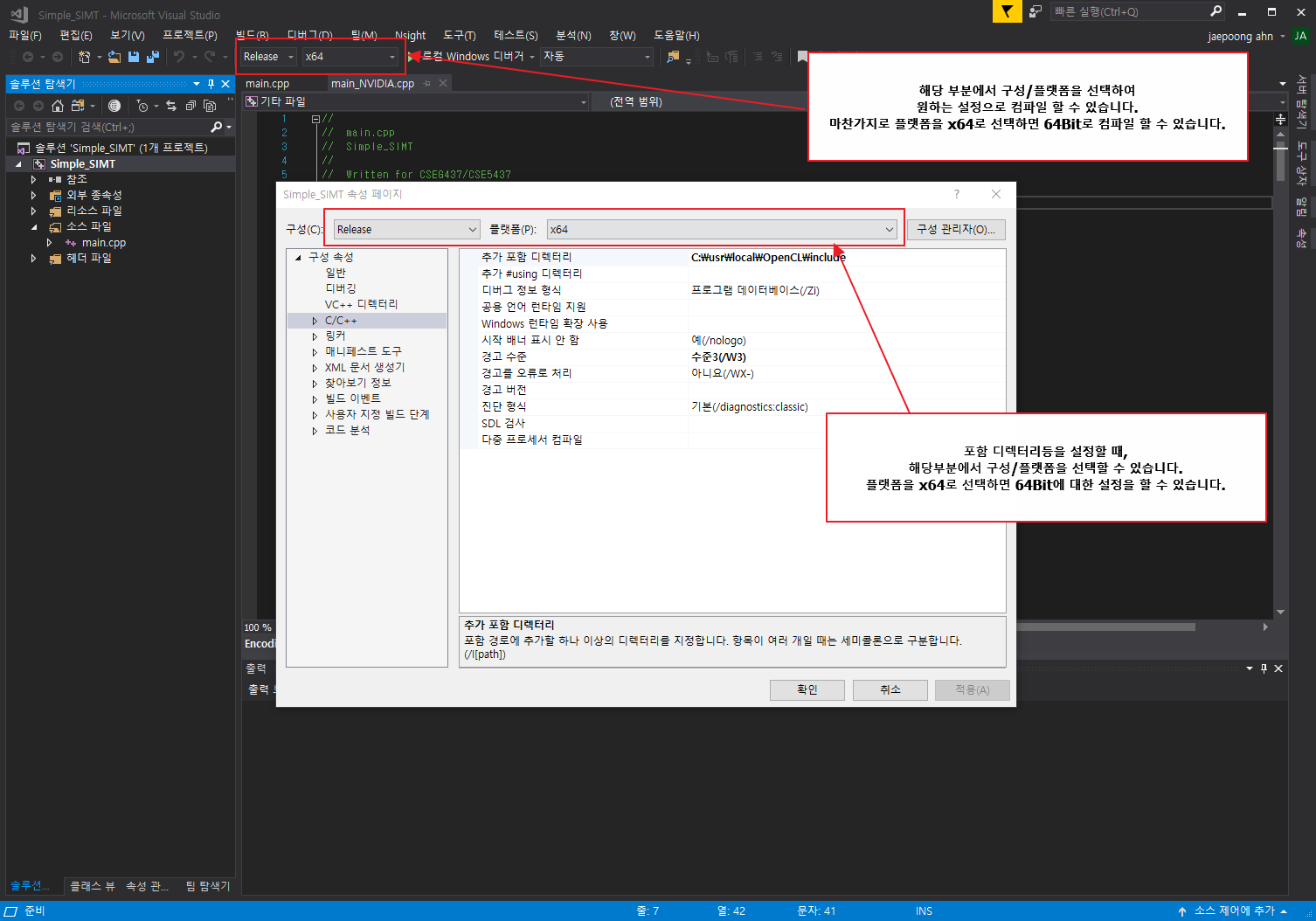
Q : OpenCL에서 local memory를 어떻게 사용하나요?
A : 첫번째 방법으로는 kernel 함수 내부에서 __local Array[SIZE] 와 같이 정적인 크기로 선언하는 것입니다.
두번째 방법으로는 clSetKernelArg([사용할 Kernel], [Argument 번호], [사용할 local memory 크기], NULL); 로 메모리를 할당하여 사용할 수 있습니다...
--------------------------------------------------------------------------------------------------------------------------------
# 2018/04/10 추가
Q : 2차원 데이터 처리는 어떻게 하나요? (이전 질문 보충 설명)
A : 예를 들어 A[ 16][ 16 ]의 경우에는 A[ 16 * 16 ]의 형태로 만들어 커널로 보내십시오.
다시 말하자면 데이터는 1차원으로 보내고, 커널에서의 접근만 (workgroup) 2차원으로 하시면 됩니다.
Q :시간측정의 기준은 어떻게 되나요? (이전 질문 보충 설명)
A : 커널 수행부터 계산 결과 로딩을 지나 후처리까지 하여 계산 완료되는 순간까지 입니다.
아래는 예시입니다.
// 측정 시작
clFinish([사용할 커맨드 큐]);
CHECK_TIME_START;
// 커널 수행
errcode_ret = clEnqueueNDRangeKernel(~~~);
// GPU 연산 결과 로드
errcode_ret = clEnqueueReadBuffer(~~~);
// 계산 결과를 출력하기 위한 후처리 (부분합을 더하는 과정 등, 알고리즘마다 없을 수도 있음)
SumAllPartitialSum();
// 측정 끝
clFinish([사용한 커맨드 큐]);
CHECK_TIME_END(compute_time);
Q : CPU와 GPU 계산이 약간 다르게 나옵니다.
A : 어떻게 코딩을 하였는가에 따라 같게 나올 수도, 다르게 나올 수 있습니다.
다르게 나왔다면 다르게 나온 이유를 기술하여야 합니다.
--------------------------------------------------------------------------------------------------------------------------------
# 2018/04/11 추가
Q : 보고서를 작성할 때, 위에 설명한 시간측정의 기준 이외에 추가적으로 시간 측정한 것을 사용해도 되나요? (이전 질문 보충 설명)
A : 네, 분석에 필요하다고 생각되면 추가적으로 특정 부분에 대하여 시간 측정을 해도 됩니다.
4/10일에 게시판에 추가한 답변 중 시간 측정에 관한 부분은 전반적인 프로그램 수행시간을 측정하는 것으로, 기본적으로 분석해야 하는 부분입니다.
(CPU 계산과 4개의 커널 프로그램의 수행시간 비교)
만약 보고서를 작성할 때, 필요하다면 측정하는 부분을 분할/추가하여 비교할 수는 있습니다.
예를 들어 GPU 연산 부분만 비교한다면 후 처리로 작성되는 CPU부분은 배제하고 측정하여 비교할 수는 있습니다.
이 답변은 보고서를 어떻게 작성하는가에 따라 필요하지 않을 수도 있습니다.
Q : (채점 관련 설명)
A : 채점은 위의 채점 기준에서 언급하였듯이 보고서인 Readme를 기준으로 채점합니다.
작성한 내용을 Readme에 기술하지 않으면서 코드 주석에만 언급하지 마십시오.
기준은 1803HW1.pdf에 언급한 내용을 기반으로 정해집니다.
위에 작성된 채점 기준을 읽고 코드와 보고서를 작성하기 바랍니다.
해당 부분은 과제를 메일로 보낼 때 (3/29) 이 게시판에 이미 언급한 내용입니다.
--------------------------------------------------------------------------------------------------------------------------------
# 2018/04/12 추가
Q : 2차원 데이터? (이전 질문 보충 설명)
A : Workgroup 구성과 데이터 접근에 대한 부분은 앞으로도 계속 질문이 올 것 같아 따로 글을 작성하였습니다.
http://grmanet.sogang.ac.kr/xe/index.php?mid=gpu18&document_srl=1136 을 참조하시기 바랍니다.
--------------------------------------------------------------------------------------------------------------------------------
ChangeLog
----------------------------------------------------------------
# 2018/04/12
요구사항 질문에 대한 답변 보완설명
제출 시 주의사항 추가 (다음 과제에도 적용)
----------------------------------------------------------------
# 2018/04/11
요구사항 질문에 대한 답변 보완설명
제출에 구글 드라이브 등의 클라우드 링크를 받지 않는다고 명시
----------------------------------------------------------------
# 2018/04/10
요구사항 질문에 대한 답변 보완설명
----------------------------------------------------------------
# 2018/04/06
요구사항 질문에 대한 답변 추가
----------------------------------------------------------------
# 2018/04/04
프로그램 채점 기준에 플랫폼 부분 추가
요구사항 질문에 대한 답변 추가
----------------------------------------------------------------
# 2018/03/30
프로그램 채점 기준에 cmake 기준 추가
----------------------------------------------------------------
# 2018/03/29
과제 시작 및 공지
----------------------------------------------------------------
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 과제 4 (2018/06/26 18:30 수정) | grmanet | 2018.06.12 | 502 |
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 과제 3 (2018/06/26 17:00 수정) | grmanet | 2018.06.04 | 518 |
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 기말고사 | grmanet | 2018.06.04 | 226 |
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 과제 2 (2018/05/19 21:30 수정) | grmanet | 2018.05.03 | 1041 |
| 공지 | 수치 컴퓨팅 및 GPU 프로그래밍 - 중간고사 | grmanet | 2018.04.09 | 331 |
| » | 수치 컴퓨팅 및 GPU 프로그래밍 - 과제 1 (2018/04/12 19:50 수정) | grmanet | 2018.03.29 | 1697 |
| 공지 | 2018 1학기 수치 컴퓨팅 및 GPU 프로그래밍 게시판입니다. | grmanet | 2018.03.29 | 331 |
| 2 |
OpenCL Workgroup 구성과 데이터 접근 (2018.04.12 16:40 수정)
| grmanet | 2018.04.12 | 303 |
| 1 |
OpenCL 코드 플랫폼 설정 방법
| grmanet | 2018.04.04 | 776 |